OCR
OCR is the process which extracts text information from the scanned document and makes them searchable.
By default, ocr process is triggered automatically on document file upload. The OCR process status is indicated by little circle next to document's title. When OCR process is completed new document version is created and document becomes searchable.
Default OCR Language
In order to perform OCR on the document you need to indicate beforehand the language of respective document. When you click "Run OCR" in document viewer you will need to choose OCR language.
When you upload documents, the value of PAPERMERGE__OCR__DEFAULT_LANGUAGE
indicates OCR language system will use (if you don't change anything it will use deu,
which stands for German).
Question
Or maybe UI should ask user OCR language on upload as well, some sort of modal dialog which appears when user drops docs/clicks upload? Or there should be an UI preference where user can opt which way he/she wants to indicate default OCR language without being ask on every doc upload? Open a disscussion on this topic and let's disscuss it!
Status Indicator
Papermerge features real time OCR status indicator - this means that you can see document's OCR status updates as they happen (i.e. in real time). The OCR status is displayed by a small circle next to the document's title. The status indicates has following meanings:
- gray circle - status is unknown (figure 1)
- orange still circle - document was scheduled for OCR (figure 2)
- orange rotating circle - document's OCR process is in progress (figure 3)
- green check - document's OCR process completed successfully and document is now searchable (figure 4)
- red cross - document's OCR process failed.



OCRed Text Layer
Once OCR process completed successfully a new document version is created -
version with OCRed text layer. This version is available for download from
the Download dropdown in document view.

Note
Under the hood Papermerge uses awesome OCRmyPDF utility to create OCRed text layer. Thus, in respect of OCRed text layer, Papermerge acts like a graphical user interface for OCRmyPDF.
Document OCRed Text
You can view OCRed text of the entire document either from commander or from viewer, in both cases choose "OCRed Text" from context menu:

If you want to see OCRed text of entire document (to be exact - all pages of the last document version) from the viewer - just make sure that no pages are selected:

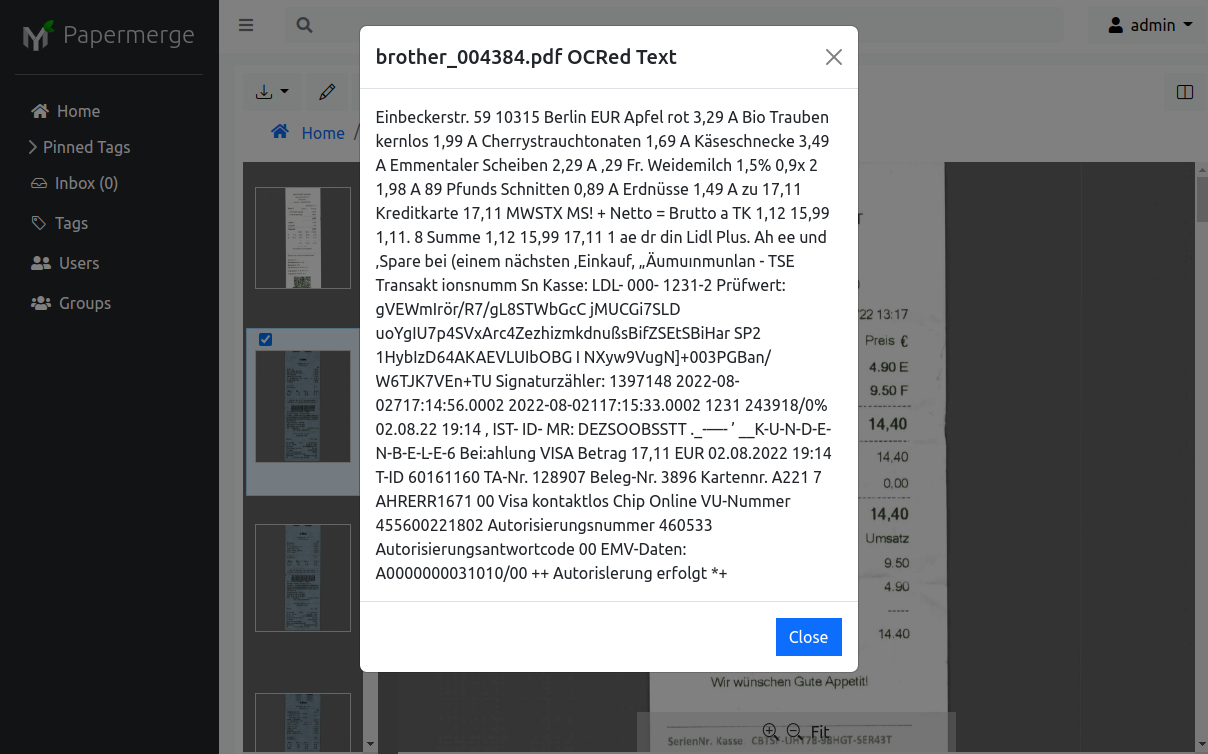
Selected Pages OCRed Text
In case document has many pages and you are interested in OCRed text of one (or multiple) very specific pages, then select pages first and then from context menu choose "OCRed Text" item:

Note
In case there are selected pages, OCRed Text menu item will show you OCRed text ONLY of the selected pages.
OCR Languages Support
Papermerge uses Tesseract to extract text from scanned documents. Tesseract supports over 130 languages - thus with Papermerge you can have documents in any of those languages.